2 点赞
systick只有16mS
使用STM32CubeMx配置RTthread,systick时间异常
6 点赞
【RT-Thread原创征文】我是开发者,我要来分享(还有新人参与奖噢)
你的宝贵经验,可能会让初学者少走很多弯路;你的一个分享,可能让一些人恍然大悟;你的一篇文章,可能会引起众人的共鸣...
2 点赞
学习art-pi ,ntp同步网络时间+led液晶屏显示+dht11获取温湿度
学习art-pi ,ntp同步网络时间+led液晶屏显示+dht11获取温湿度
2 点赞
2 点赞
RT-Thread 隐藏的宝藏之 data_queue
数据队列能够接收来自线程中不固定长度的数据,数据 **不会** 缓存在自己的内存空间中,自己的内存空间只有一个指向这包数据的指针。其他线程也能够从数据队列获取数据,当数据队列为空的时候,可以挂起线程。当有新的数据到达时,挂起的线程将被唤醒以接收并处理消息。数据队列是一种异步的通信方式。
3 点赞
深入理解 volatile 关键字
从编译器的角度触发深入理解 volatile 关键字。
3 点赞
RTOS 性能测试相关概念说明
讲解 RTOS 性能测试以及临界区保护相关概念。
7 点赞
中科蓝讯 AB32VG1 RISC-V开发板模块评测任务大挑战
本次评测开发板:中科蓝讯 AB32VG1开发板
3 点赞
Lwip 内存系统说明
解释 lwip 的内存分配机制,以及在应用 lwip 时可能遇到的内存错误查找过程。
1 点赞
IRQ 和 FIQ 的区别
讲解 IRQ 和 FIQ 的区别,以及 FIQ 为什么处理速度快于 IRQ。
4 点赞
【社区福利】喜迎元宵,论坛积分换好礼
超多礼品等你来兑换~
1 点赞
IDLE 线程其实很忙的
讲述 rt-thread 线程的功能以及其面临的风险。
1 点赞
【STM32L475】RT-Thread Freemodbus RS485主机
【STM32L475】RT-Thread Freemodbus RS485主机
4 点赞
3 点赞
1 点赞
Art-Pi学习笔记9:如何为Art-pi的内部flash设置读保护
学习使用STM32CubeProgrammer的读保护配置和批量烧录功能
3 点赞
RT-Thread 隐藏的宝藏之等待队列
等待队列:等待其他线程的 wake_up 讯息来唤醒自己
3 点赞
Rt-thread Ymodem的详细使用方法
RTT官方有关于Ymodem的使用方法并没有详细的说明,在自己摸索了很久之后写了一些操作方法给大家
8 点赞
2 点赞
用OpenCV实现超轻量的NanoDet目标检测模型!| 转载极市平台
关于轻量级目标破检测模型,之前已经有在 rt-thread 公众号推送过,比较有好的有两个:
一个是1.8M 大小的NanoDet;
一个是1.3M 大小的yolo-fastest;
本文主要讲的是 NanoDet,后续可能会跟上NanoDet的相关文章
本文作者用OpenCV部署了超轻量目标检测模型NanoDet,并实现了C++和Python两个版本,并对此进行了解析,附完整代码。
Github: https://github.com/hpc203/nanodet-op
1 点赞
0 点赞
数据科学中常见的9种距离度量方法,内含欧氏距离、切比雪夫距离等 | 转载机器之心
在数据挖掘中,我们经常需要计算样本之间的相似度,通常的做法是计算样本之间的距离。在本文中,数据科学家 Maarten Grootendorst 向我们介绍了 9 种距离度量方法,其中包括欧氏距离、余弦相似度等。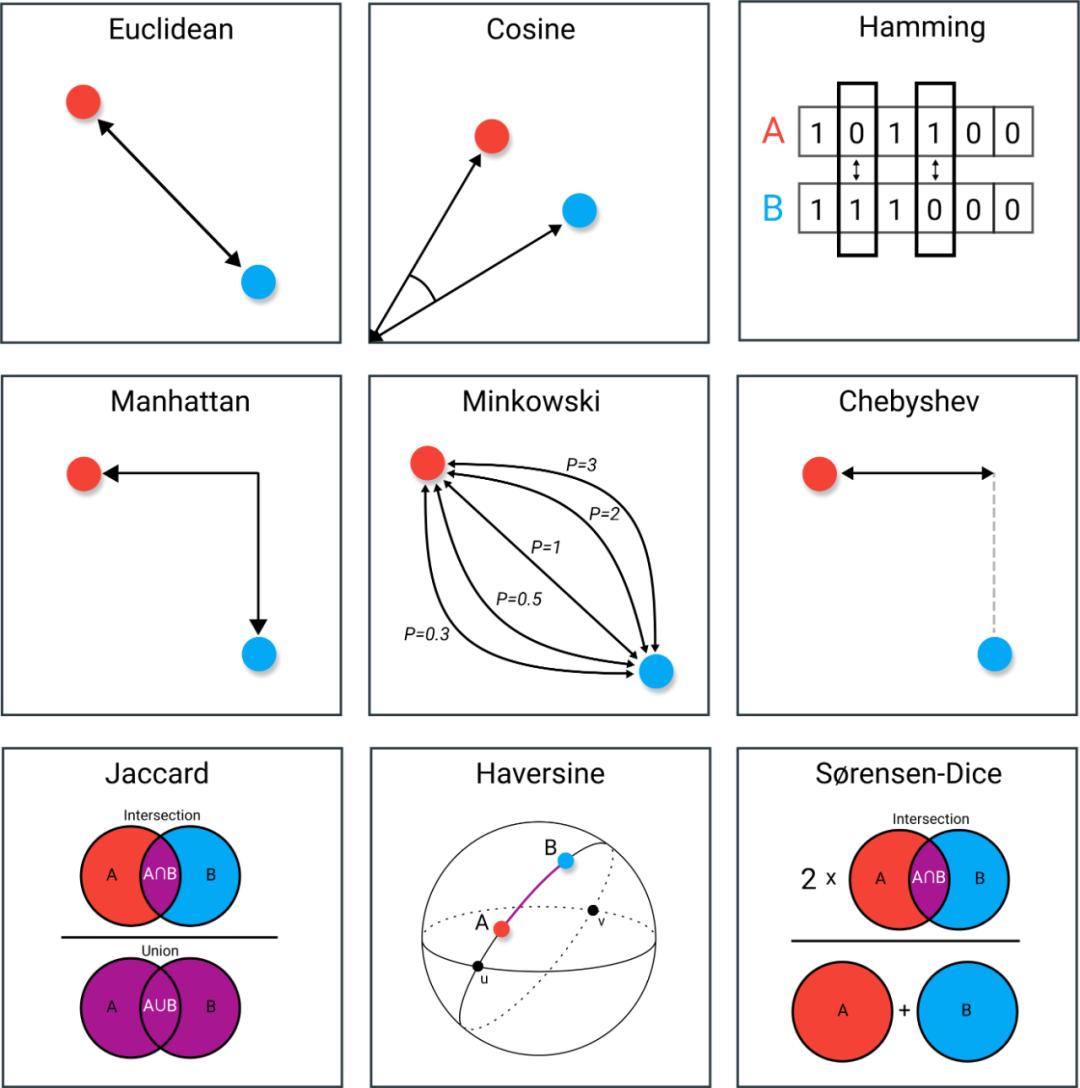许多算法,无论是监督学习还是无监督学习,都会使用距离度量。这些度量,如欧几里得距离或者余弦相似性,经常在 k-NN、 UMAP、HDBSCAN 等算法中使用。了解距离
1 点赞
1 点赞
1 点赞
用VS Code直接浏览GitHub代码 | 12.1K星 | 转载量子位
“看GitHub代码”这件事上,还在网页上点点点?
用开发工具看代码,不香吗?
于是,它来了,它来了——可以直接用VS Code方式打开GitHub代码的工具。
*github1s项目地址:
https://github.com/conwnet/github1s*
*surf.项目地址:
https://github.com/surfcodes/surf*
0 点赞
DeepMind最新研究NFNet:抛弃归一化,准确率新高 | 转载机器之心
深度学习,已经不需要归一化了。
我们知道,在传递给机器学习模型的数据中,我们需要对数据进行归一化(normalization)处理。
在数据归一化之后,数据被「拍扁」到统一的区间内,输出范围被缩小至 0 到 1 之间。人们通常认为经过如此的操作,最优解的寻找过程明显会变得平缓,模型更容易正确的收敛到最佳水平。
然而这样的「刻板印象」最近受到了挑战,DeepMind 的研究人员提出了一种不需要归一化的深度学习模型 NFNet,其在大型图像分类任务上却又实现了业内最佳水平(SOTA)
1 点赞
DeepMind丢掉了归一化,训练速度提了8.7倍 开源 | 转载量子位
对于大多数图像识别模型来说,批处理归一化(batch normalization)是非常重要的组成部分。
但与此同时,这样的方式也存在一定的局限性,那就是它存在许多并不重要的特征。
虽然近期的一些研究在没有归一化的情况下,成功训练了深度ResNet,但这些模型与最佳批处理归一化网络的测试精度不相匹配。
而这便是DeepMind此次研究所要解决的问题——提出了一种自适应梯度剪裁 (AGC) 技术。
具体而言,这是一种叫做Normalizer-Free ResNet (NFNet)的新
9 点赞
【再见,2020】+RT_THREAD我想对你说
经验,笔记,建议。
3 点赞
6 点赞
RT-Thread 隐藏的宝藏之双链表
RT-Thread 的内核源码中通过双链表来实现了所有 `object` 连在了一起,掌握链表后,对分析,学习 RT-Thread 的思想一定会事半功倍
推荐文章





